Helios Performance Optimization¶
Overview¶
This document provides guidance on design patterns, tips, and tricks to maximize Helios performance and resource utilization with the Guppy programming language.
Key user benefits include:
Early Exit: features to terminate a job, or to quit a shot.
Delayed Initialization: Reduce idle time on qubits by resetting or delaying qubits required later in program.
Deferred Measurements: General recommendation is to defer measurements to reduce the number of flushes by the runtime.
1-Qubit Gate Squashing: A mathematical formula for transforming multiple consecutive 1Q gates on a given qubit to an equivalent single 1Q gate on that qubit. The calculation computing the angle resulting from multiple 1Q rotations is performed at runtime reducing the number of physical 1Q gates performed, which in turn increases fidelity and reduces execution time.
Quantinuum Helios enables execution of Guppy programs, in particular programs using unique features, such as mid-circuit measurement, classical control flow, arithmetic, and dynamic qubit reuse. These programs are compiled in real time rather than fully scheduled ahead of execution, enabling the software to make decisions on ion transport, batching, and operation ordering based on the current physical state of the machine. This approach is essential for scaling because it decouples algorithm design from the low-level constraints of ion transport and laser availability while still exposing enough structure for optimization on the backend. All operations performed by the runtime use the universal native gateset of Helios. The helios compiler is responsible for alignment and decompositions of non-native gates (requested by the user program) to native gates.
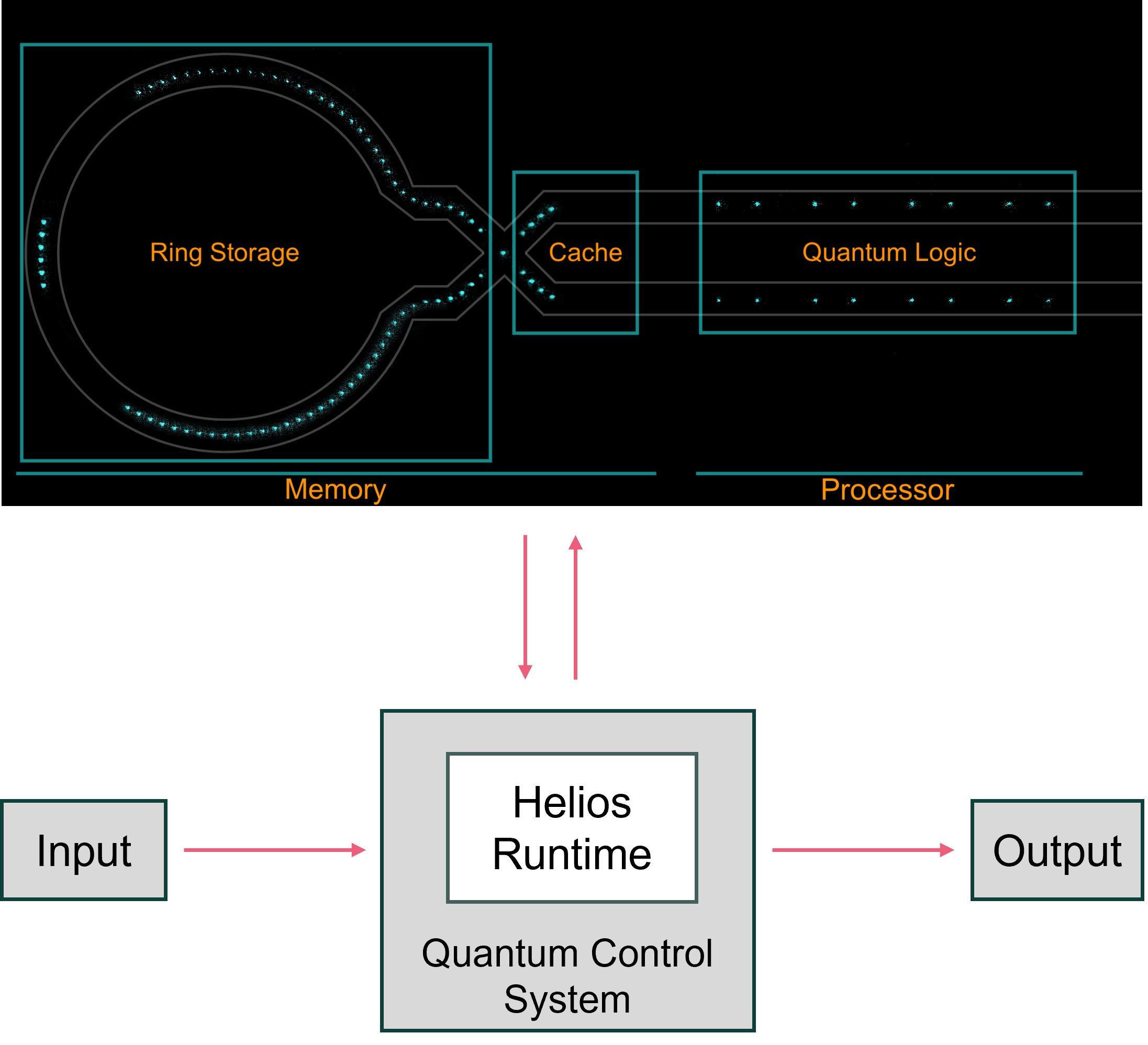
The quantum control system used by Helios includes a quantum runtime to stream quantum operations to the 98-qubit Helios trapped-ion quantum computer during real-time execution. It coordinates ion transport, cooling, and quantum gates across spatially separated memory and logic regions using a real-time decision engine rather than a static schedule. By tightly integrating control software with the QCCD hardware, especially the junction-based transport and batch-oriented logic zones, Helios can overlap transport, cooling, and computation, reducing idle time and improving throughput. Together, Guppy and the Helios runtime demonstrate a scalable model for quantum control in which expressive programming, dynamic compilation, and hardware-aware execution are co-designed to support increasingly complex quantum workloads on large trapped-ion systems.
Early Exit¶
Guppy provides two built-in functions for early exit. guppylang.std.builtins.panic() fully terminates program execution. guppylang.std.builtins.exit() terminates only the current shot but allows program execution to continue. Both functions can be triggered by users when specific checks or conditions are satisfied during real-time execution.
Note
Also see postselection at Guppy Langauge Guide.
Panic¶
guppylang.std.builtins.panic() indicates an unexpected, fatal error. It immediately aborts the entire program, and no further shots are executed. This is analogous to a runtime exception in classical programming.
Intended behavior:
Stops the entire program
No further shots are executed
Triggers an error condition
Used for unexpected or invalid states
Panic-induced exits imply 1 or more abnormalities during program execution.
from guppylang import guppy
from guppylang.std.quantum import measure, qubit, h
from guppylang.std.builtins import panic, result
@guppy
def main() -> None:
q = qubit()
h(q)
outcome = measure(q)
if outcome:
panic("Postselection failed")
result("c", outcome)
hugr = main.compile()
from selene_sim import Stim, build
from selene_sim.result_handling.parse_shot import postprocess_unparsed_stream
runner = build(main.compile(), "panic")
shots, error = postprocess_unparsed_stream(
runner.run_shots(
Stim(),
n_qubits=11,
n_shots=100,
random_seed=1,
parse_results=False,
)
)
print(error)
print(shots)
Panic (#1001): Postselection failed
[[('USER:BOOL:c', 0)], [('USER:BOOL:c', 0)], [('EXIT:INT:Postselection failed', 1001)]]
Exit¶
guppylang.std.builtins.exit() ends the current shot only, then execution continues with the next shot. It is intended for control‑flow decisions, such as:
Postselection
Early rejection of invalid measurement outcomes
Retry‑style logic across shots
The program itself is considered successful.
from guppylang import guppy
from guppylang.std.quantum import measure, qubit, h
from guppylang.std.builtins import exit, result
@guppy
def main() -> None:
q = qubit()
h(q)
outcome = measure(q)
if outcome:
exit("Postselection failed", 42)
result("outcome", outcome)
hugr = main.compile()
from selene_sim import Stim, build
from selene_sim.result_handling.parse_shot import postprocess_unparsed_stream
runner = build(main.compile(), "exit")
shots, error = postprocess_unparsed_stream(
runner.run_shots(
Stim(),
n_qubits=1,
n_shots=10,
random_seed=1,
parse_results=False,
)
)
print(error)
print(shots)
None
[[('USER:BOOL:outcome', 0)], [('USER:BOOL:outcome', 0)], [('EXIT:INT:Postselection failed', 42)], [('EXIT:INT:Postselection failed', 42)], [('USER:BOOL:outcome', 0)], [('USER:BOOL:outcome', 0)], [('EXIT:INT:Postselection failed', 42)], [('EXIT:INT:Postselection failed', 42)], [('EXIT:INT:Postselection failed', 42)], [('USER:BOOL:outcome', 0)]]
Out of Qubits Errors¶
guppylang.std.quantum.maybe_qubit() is Guppy’s safe qubit allocation primitive. It returns Option[qubit], not a qubit. Users must explicitly handle success vs failure. It enables resource‑aware programs. The panic function can be used to terminate the program if more qubits are not available for allocation.
from guppylang import guppy
from guppylang.std.quantum import qubit, maybe_qubit, h, measure
from guppylang.std.builtins import panic, result
@guppy
def main() -> None:
# Try to allocate a qubit
q0 = qubit()
mq = maybe_qubit()
# If allocation fails, abort execution
if mq.is_nothing():
panic("No more qubits available to allocate.")
# Allocation succeeded
q = mq.unwrap()
h(q)
m = measure(q)
h(q0)
c = measure(q0)
# Record a classical result for this shot
result("m", m)
result("c", c)
hugr_program = main.compile()
from selene_sim import Stim, build
from selene_sim.result_handling.parse_shot import postprocess_unparsed_stream
runner = build(main.compile(), "panic")
shots, error = postprocess_unparsed_stream(
runner.run_shots(
Stim(),
n_qubits=1,
n_shots=10,
random_seed=1,
parse_results=False,
)
)
print(error)
print(shots)
Panic (#1001): No more qubits available to allocate.
[[('EXIT:INT:No more qubits available to allocate.', 1001)]]
Deferred Measurements¶
Users should request measurements as late as possible. It is important to understand that while guppylang.std.quantum.measure() returns a bool on the surface, on Quantinuum systems the physical measurement doesn’t always happen immediately. A measurement call requests a measurement, which can then be deferred until it is actually required. At that point, any further execution is blocked, so by delaying it we give the runtime more opportunities to parallelise operations between request and block.
In deferred_1, each measure function is followed by a result on the measurement outcome. Using result forces an immediate measurement of q, which isn’t the best for performance. In deferred_2, the measure operations are delineated from the result call. This enables better opportunity for parallelization of primitive operations, because the measurement is not called until it’s required. This is demonstrated by the visualization below. The left plots operations requested by deferred_1, whilst the right plots deferred_2. Due to the trick used in deferred_2, the resulting programming better exploits parallelization of primitive operations, reduces idle time on qubits and improves the shot execution time by 90%.
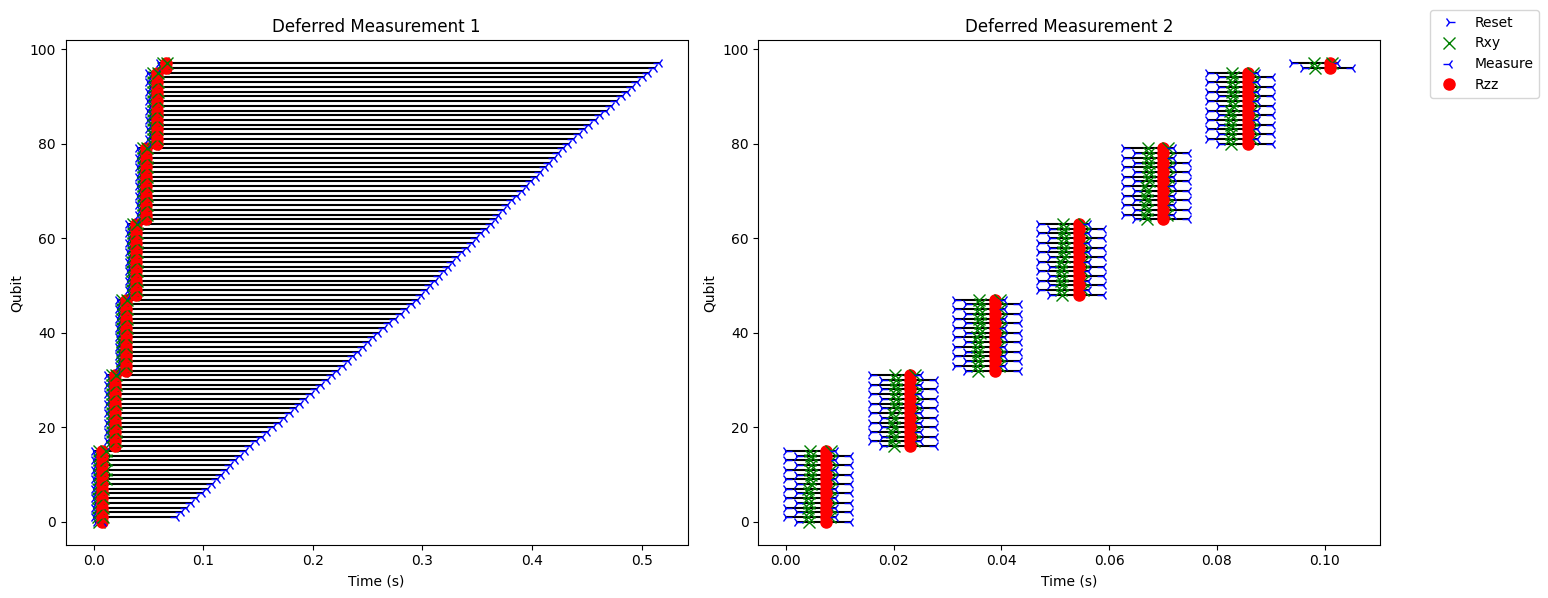
Note
The measurements are coupled with result calls on the measurement outcome. This program does not exploit parallelization of operations very well.
from guppylang import guppy
from guppylang.std.builtins import comptime, array, result
from guppylang.std.qsystem import measure_leaked, zz_max, phased_x
from guppylang.std.quantum import qubit, h, cx
N_QB = 16
@guppy
def deferred_1() -> None:
qs = array(
qubit()
for _ in range(comptime(N_QB))
)
for i in range(comptime(N_QB // 2)):
h(qs[i * 2])
cx(qs[i * 2], qs[i * 2 + 1])
for q in qs:
m = measure_leaked(q)
if m.is_leaked():
m.discard()
result("c", 2)
else:
result("c", m.to_result().unwrap())
hugr_deferred_1 = deferred_1.compile()
In deferred_2, measurements are deferred by decoupling from result function on measurement outcome. This enables better opportunity for parallelization of primitive operations, because the measurement is not called until it’s required.
@guppy
def deferred_2() -> None:
qs = array(
qubit()
for _ in range(comptime(N_QB))
)
for i in range(comptime(N_QB // 2)):
h(qs[i * 2])
cx(qs[i * 2], qs[i * 2 + 1])
measurements = array(
measure_leaked(q) for q in qs
)
for m in measurements:
if m.is_leaked():
m.discard()
result("c", 2)
else:
result("c", m.to_result().unwrap())
hugr_deferred_2 = deferred_2.compile()
Delayed Initializations¶
A simple yet effective optimization is to ensure that ancillary qubits (ancillas) are not allocated and initialized prematurely. Currently, this can be achieved by explicitly guiding the compiler to delay qubit allocation and initialization until as late as possible. In practice, this is done by placing a barrier that includes both the data qubits and the ancillas, followed immediately by a reset of the ancilla qubits just before they are first used. The effect of not applying this optimization is illustrated on the left-hand side of the figure. This graphical representation shows circuit execution on the Helios system, where time progresses from left to right along the horizontal axis, and the vertical axis indexes individual qubits. If one declares an array of data qubits and an array of ancilla qubits, performs a sequence of gates on the data qubits, and only later applies gates involving both data and ancilla qubits, the ancillas are nevertheless initialized at the beginning of the circuit. This behavior is suboptimal, as it introduces extended idle periods for the ancilla qubits during which they are susceptible to memory errors.
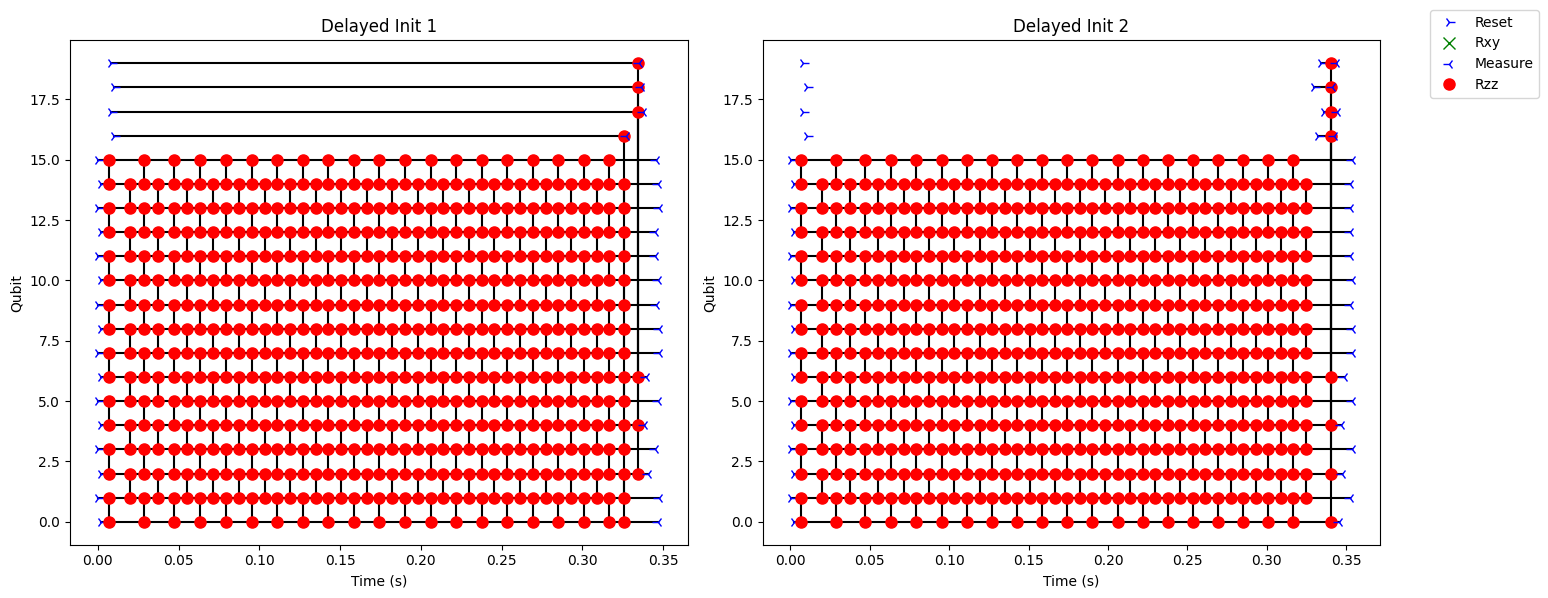
This issue can be addressed straightforwardly by inserting the barrier–reset pattern shown in the code sketch on the right-hand side. With this modification, the circuit execution diagram demonstrates that the ancilla qubits—shown at the top—are not initialized until immediately before they are required. As a result, idle time is minimized and exposure to memory decoherence is reduced, leading to improved overall circuit reliability.
This first example is suboptimal and corresponds to the circuit diagram on the left. The ancilla qubits are not reset prior usage, leading to long idle time. The ancilla qubits are susceptible to memory errors. The program applies brickwork layers to the data qubits, qs, before entangling with ancilla qubits, qa.
from guppylang import guppy
from guppylang.std.quantum import measure_array, qubit, reset
from guppylang.std.qsystem import zz_max
from guppylang.std.builtins import array, comptime, result, barrier
N_QB = 16
N_QA = 4
N_LOOPS = 20
@guppy
def even_layer(
qs: array[qubit, comptime(N_QB)]
) -> None:
for i in range(comptime(N_QB)):
if i % 2:
continue
zz_max(qs[i], qs[i + 1])
@guppy
def odd_layer(
qs: array[qubit, comptime(N_QB)]
) -> None:
for i in range(comptime(N_QB-1)):
if not i % 2:
continue
zz_max(qs[i], qs[i + 1])
@guppy
def ancilla_layer(
qs: array[qubit, comptime(N_QB)],
qa: array[qubit, comptime(N_QA)]
) -> None:
for i in range(comptime(N_QA)):
zz_max(qs[2*i], qa[i])
@guppy
def main() -> None:
qs = array(
qubit() for _ in range(comptime(N_QB))
)
qa = array(
qubit() for _ in range(comptime(N_QA))
)
for _ in range(comptime(N_LOOPS)):
even_layer(qs)
odd_layer(qs)
ancilla_layer(qs, qa)
result("a", measure_array(qa))
result("c", measure_array(qs))
The second example introduces a barrier-reset pattern, delaying ancilla initialization until the ancillas are required by primitive operations. The memory error vulnerability is removed.
@guppy
def main1() -> None:
qs = array(
qubit() for _ in range(comptime(N_QB))
)
qa = array(
qubit() for _ in range(comptime(N_QA))
)
for _ in range(comptime(N_LOOPS)):
even_layer(qs)
odd_layer(qs)
barrier(qs, qa)
for i in range(comptime(N_QA)):
reset(qa[i])
ancilla_layer(qs, qa)
result("a", measure_array(qa))
result("c", measure_array(qs))
Loop Ordering¶
Loop orderings can impact opportunities for parallelization and the overall shot execution time. Two looping functions are presented below, loop_ordering1 and loop_ordering2. Each function relies on nested FOR loops to apply pairwise cx operations, across 36 qubits over 200 iterations. loop_ordering1 iterates over pairs of qubits (outer loop), and then runs 200 iterations on that specified pair. The runtime is inefficient at exploiting parallelization across these operations. In contrast, loop_ordering2 switches the outer loop and the inner loop. Each iteration in the outer loop requests, performs a second inner loop that requests cx operations on all pairs of qubits. This runtime is more effective at parallelizing 2-qubit gate operations for the second program, leading to a 25% improvement in the circuit execution time.
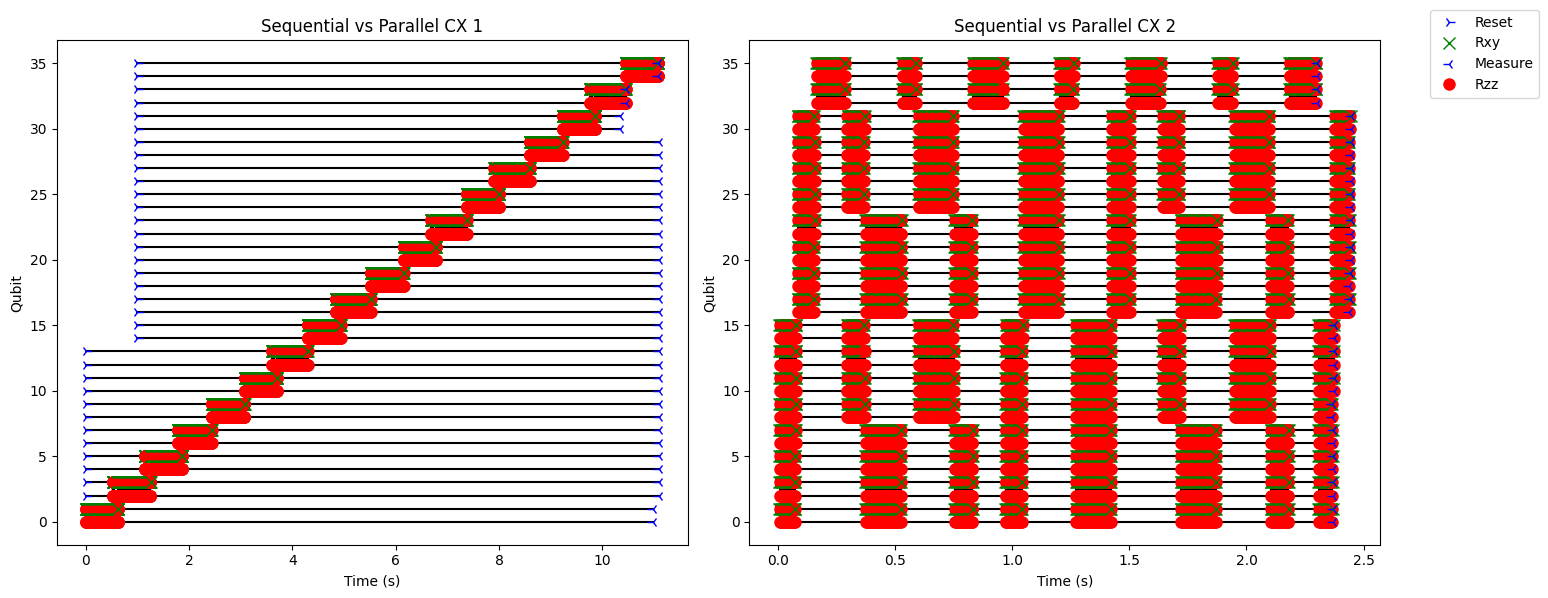
loop_ordering1 iterates over pairs of qubits (outer loop), and then runs 200 iterates on that specified pair. The runtime is inefficient at exploiting parallelization across these operations.
from guppylang import guppy
from guppylang.std.builtins import comptime, array, result
from guppylang.std.quantum import measure_array
from guppylang.std.quantum import qubit, cx
N_LOOPS = 200
N_QB = 36
@guppy
def loop_ordering1() -> None:
qs = array(
qubit() for _ in range(comptime(N_QB))
)
# Apply 200 CX gates on each pair sequentially
for i in range(comptime(N_QB // 2)):
for _ in range(comptime(N_LOOPS)):
cx(qs[i * 2], qs[i * 2 + 1])
result("c", measure_array(qs))
hugr_loop_ordering1 = loop_ordering1.compile()
loop_ordering2 switches the outer loop and the inner loop. Each iteration in the outer loop requests, performs a second inner loop that requests cx operations on all pairs of qubits. The runtime is more efficient at exploiting parallelization, leading to a 25% improvement in shot execution time.
@guppy
def loop_ordering2() -> None:
qs = array(
qubit()
for _ in range(comptime(N_QB))
)
# Apply one CX gate on each pair per iteration to enable parallelization across pairs
for _ in range(comptime(N_LOOPS)):
for i in range(comptime(N_QB // 2)):
cx(qs[i * 2], qs[i * 2 + 1])
result("c", measure_array(qs))
hugr_loop_ordering2 = loop_ordering2.compile()
Runtime Optimization¶
Guppy programs are compiled to a native representation using the Helios compiler before hardware execution. This can include realignment of non-native gates to native gates. During real-time execution, the Helios runtime tries to parallelize execution of native gates to improve execution time. The runtime is also responsible for bounded compilation of gating operations requested by the user. Once the runtime data structure is filled, or if the quantum control system requests a measurement result, the runtime performs tasks during routing to the field-programmable gate array (FPGA):
Perform 1-qubit gate squashing.
Calculate transport operations for the queued primitive operations.
Batch primitive operations to exploit parallelization across groups of 16 qubits.
Dynamically allocate ions.
Runtime behavior is not specifiable by the user.
1-Qubit Gate Squashing¶
Note
This capability is performed by default during hardware execution.
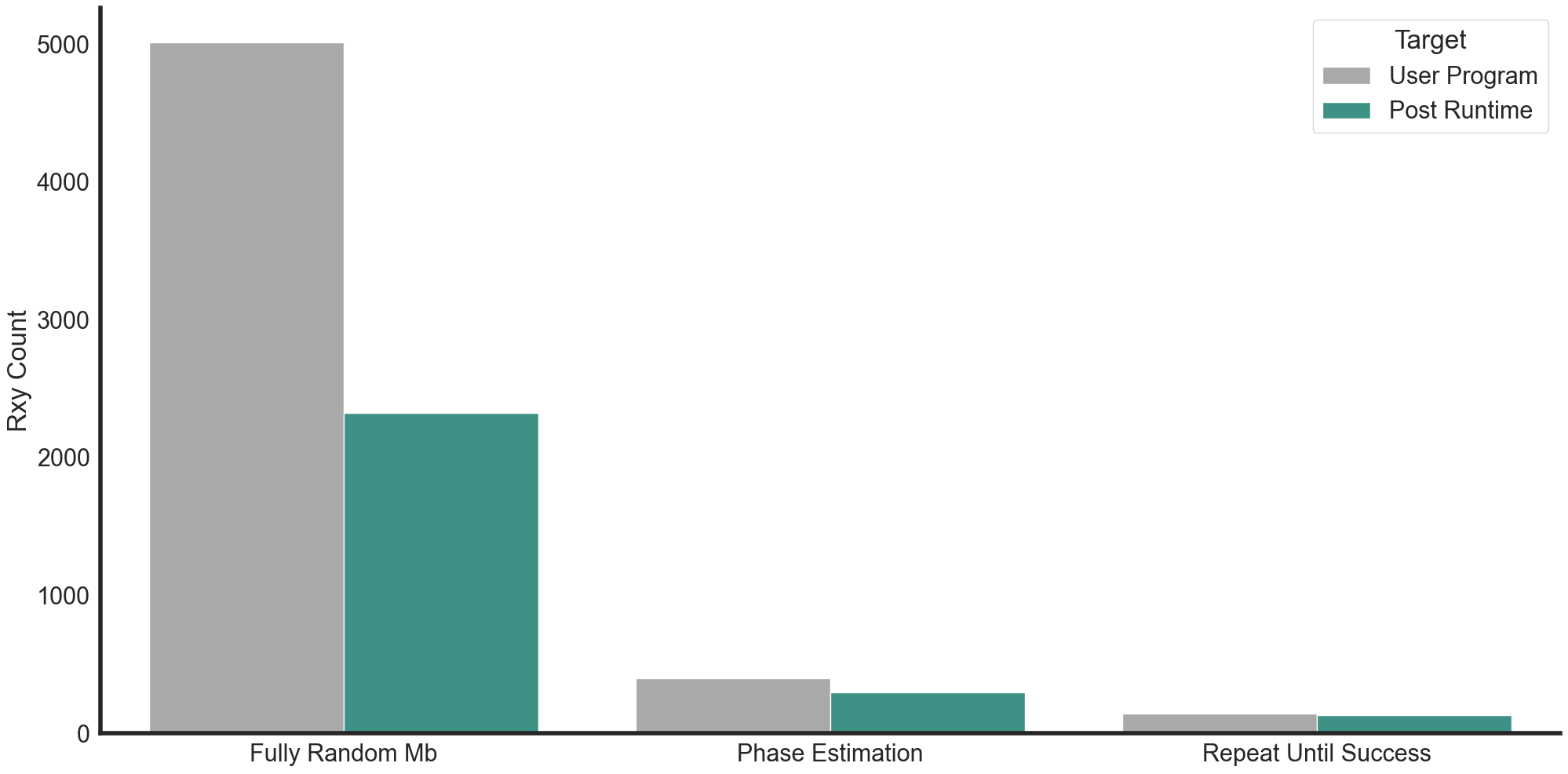
The Helios runtime squashes 1-qubit gates during real-time execution. The runtime can queue requests for gating operations. Where possible, 1-qubit rxy gates are squashed to optimize the user program. Additionally, rz gates are elided. As a consequence, the user program may have different resource statistics pre- and post-runtime optimization.
The figure above shows a reduction in the physical 1-qubit (rxy) gate count. “User Program” corresponds to the pre-runtime optimization statistics. “Post Runtime” corresponds to post-runtime optimization statistics. Full random mirror benchmarking benefits from ~50% improvement in Rxy count. Phase Estimation benefits from a ~25% improvement in Rxy count. There are also programs with negligble change to the rxy gate count, such as a 3-qubit Repeat Until Success (RUS) program with 1000 iterations.
Transport Model¶
Quantum operations on Helios are realized by dynamically sorting qubits from a ring‑shaped storage region into the radial legs of the trap, where quantum gates are executed. Qubit transport and gate execution are therefore tightly coupled to the physical sorting architecture.
Operations are executed in fixed-size batches: specifically, up to 16 qubits or eight 2‑qubit gates can be operated on concurrently within a single execution window. After completing a batch, the involved qubits either return to the storage ring or are transported further into the trap legs to participate in subsequent operations.
As a consequence of this batching model, gate execution efficiency (gates per unit time) is maximized when a circuit layer contains a multiple of eight 2-qubit gates. Circuit layers that do not meet this criterion underutilize the available execution capacity and incur additional transport overhead.
Certain circuit structures are therefore inherently less efficient on Helios. For example, one‑to‑all interaction patterns or staircase‑style circuits, in which only a single 2‑qubit gate can be executed at a time, require a full sorting operation before each gate. This repeated sorting significantly increases execution latency. This behavior differs from earlier systems such as H2, reflecting Helios’ distinct qubit‑sorting architecture.
Similarly, circuits composed of alternating even‑odd gate patterns—such as 1‑dimensional brickwork circuits—require 2 complete sorting stages per layer. This requirement arises because 2 gates can only be executed for a specific orientation of ion crystals, and Helios does not support explicit swap operations to rearrange qubit ordering within a layer.
Despite these constraints, circuits with stronger local structure—such as 1‑dimensional or 2‑dimensional brickwork circuits, as well as sparser interaction graphs—can still benefit from reduced transport overhead. In such cases, locality allows partial amortization of sorting costs across layers, resulting in improved overall execution efficiency, as discussed in the subsequent analysis. The figure below shows the time budget for a 98-qubit program.
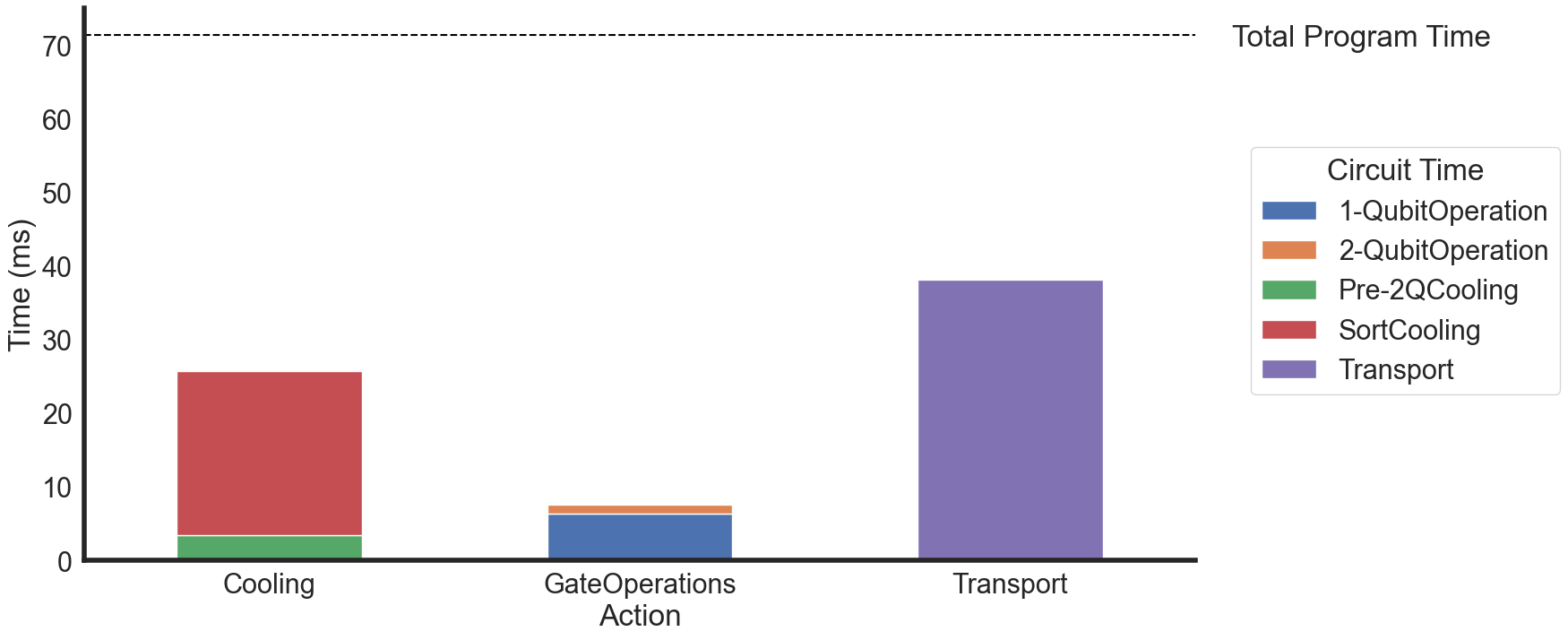
Time budget for a depth-1 program with arbitrary qubit permutations and 1Q and 2Q gates on all 98 qubits. Operations are broken down into three categories: ion transport; cooling during sorting (“sort cooling”) and before 2Q gates (“pre-2Q cooling”); and quantum operations, namely 1Q and 2Q gates.
Dynamic Qubit Allocation¶
Dynamic qubit allocation is a runtime mechanism to better utilize scarce qubit resources. During Helios operation, the runtime determines if new qubits are initialized, or existing qubits are reused upon program request for qubits. Users can request qubits on-the-fly with Guppy. However, the runtime is directly responsible for ion allocation. For multiple independent requests for qubits, the system can implicitly reuse ions. The physical ion to Guppy qubit correspondence may not be preserved during the lifetime of the program.
Function Calls and Primitive Operations¶
The Helios control system serializes function calls in the user program but parallelizes primitive (native gate) operations. Primitive operations are parallelized in groups of 16 qubits.
Grover’s Search¶
The program outlined below performs a Grover’s search. The oracle defined for this problem searches for the “111” bitstring. Grover’s search consists of multiple iterations. Each iteration applies the phase oracle and the diffusion operator to the data qubits. For a single iteration, function calls starting from the entry-point function (main) are serialized. The success probability is maximized with 2 iterations of the oracle and diffusion operator.
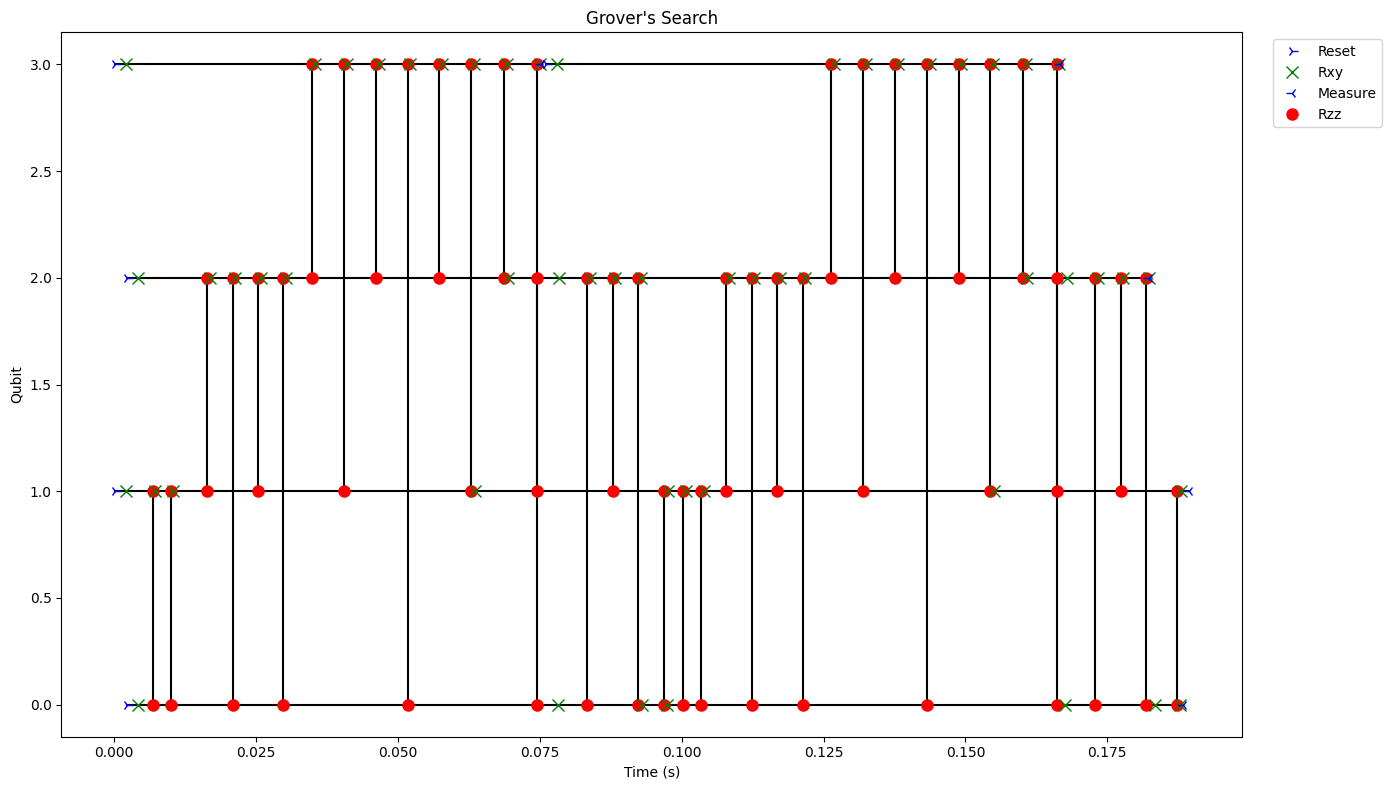
Grover’s search runtime call structure.¶
The initial function call either requests qubit allocations or returns measure outcomes; otherwise, further function calls are made by the user program.
>main
>grover_search
>oracle
>mark
>c3x
>mark
>operator
The grover_search function calls oracle and operator. The oracle function contains primitive operations but also makes other function calls, such as mark and c3x, which also contain primitive operations.
from collections.abc import Callable
from guppylang import guppy
from guppylang.std.builtins import (
array,
comptime,
result,
owned
)
from guppylang.std.angles import pi
from guppylang.std.quantum import (
qubit,
x,
h,
cx,
rz,
measure,
measure_array,
toffoli,
)
# This Grover example is a fixed 3-qubit implementation.
n = comptime(3)
@guppy
def c3x(q: array[qubit, n], target: qubit) -> None:
rz(q[0], pi * 0.125)
rz(q[1], pi * 0.125)
rz(q[2], pi * 0.125)
h(target)
cx(q[0],q[1])
rz(target, pi * 0.125)
rz(q[1], pi * 3.875)
cx(q[0],q[1])
cx(q[1],q[2])
rz(q[2], pi * 3.875)
cx(q[0],q[2])
rz(q[2], pi * 0.125)
cx(q[1],q[2])
rz(q[2], pi * 3.875)
cx(q[0],q[2])
cx(q[2],target)
rz(target, pi * 3.875)
cx(q[1],target)
rz(target, pi * 0.125)
cx(q[2],target)
rz(target, pi * 3.875)
cx(q[0],target)
rz(target, pi * 0.125)
cx(q[2],target)
rz(target, pi * 3.875)
cx(q[1],target)
rz(target, pi * 0.125)
cx(q[2],target)
rz(target, pi * 3.875)
cx(q[0],target)
h(target)
c3x.check()
@guppy
def mark(
x_array: array[int, n],
q_array: array[qubit, n]
) -> None:
for i in range(n):
if not x_array[i]:
x(q_array[i])
mark.check()
@guppy
def oracle(
x_array: array[int, n],
q_array: array[qubit, n]
) -> bool:
ancilla = qubit()
x(ancilla)
h(ancilla)
mark(x_array, q_array)
c3x(q_array, ancilla)
mark(x_array, q_array)
h(ancilla)
x(ancilla)
b = measure(ancilla)
return b
@guppy
def operator(
q_array: array[qubit, n]
) -> None:
for i in range(n):
h(q_array[i])
x(q_array[i])
h(q_array[2])
toffoli(q_array[0], q_array[1], q_array[2])
h(q_array[2])
for i in range(n):
x(q_array[i])
h(q_array[i])
@guppy
def grover_search(
x_array: array[int, n],
q_array: array[qubit, n] @owned,
phase_oracle: Callable[
[array[int, n],
array[qubit, n]],
bool
],
n_iterations: int
) -> array[bool, n]:
for _ in range(n_iterations):
_ = phase_oracle(x_array, q_array)
operator(q_array)
return measure_array(q_array)
marked_state = [1, 1, 1]
N = len(marked_state)
K = 2
@guppy
def main() -> None:
q_array = array(qubit() for _ in range(comptime(N)))
for i in range(comptime(N)):
h(q_array[i])
x_array = array(i for i in comptime(marked_state))
data_result = grover_search(x_array, q_array, oracle, comptime(K))
result("data", data_result)
hugr_program = main.compile()